

INTRODUCTION
Dans le dernier épisode du Boston Technical Blog, nous présentons la très attendue Grace Hopper Superchip de NVIDIA. Assurez-vous d'avoir votre tasse de café à portée de main et nous allons nous y mettre. Décortiquons le nom du produit : Grace Hopper était une pionnière de la programmation informatique. Elle a inventé le tout premier compilateur et co-développé le COBOL (un des premiers langages de programmation de haut niveau) qui est toujours utilisé aujourd'hui, plus de 60 ans plus tard. Le terme "Superchip" est assez explicite : il s'agit de réunir deux processeurs impressionnants dans un seul boîtier, d'où le nom de Superchip. Il faut être très confiant pour utiliser un tel nom, surtout lorsqu'il s'agit du tout premier processeur de centre de données de votre entreprise. Il est clair que NVIDIA ne plaisante pas avec le nom de ce produit. Elle l'a clairement désigné comme un produit phare, peut-être pas seulement pour elle, mais pour l'ensemble de l'industrie du HPC et de l'IA.

En quelques mots, Grace Hopper est le bloc de construction hétérogène (CPU, GPU et mémoire) de NVIDIA pour les déploiements à grande échelle de HPC et d'IA. La principale différence réside dans le fait que Grace Hopper offre jusqu'à 150 To (256 Superchips) de mémoire peer accessible, alors que les déploiements actuels utilisent la mémoire distribuée via les réseaux Ethernet et InfiniBand traditionnels - un goulot d'étranglement potentiellement énorme.
NVLINK-C2C
Vous avez peut-être déjà entendu parler de NVLink de NVIDIA, qui en est actuellement à sa quatrième génération d'interconnexion haute performance. À l'origine, NVIDIA a mis sur le marché cette interconnexion pour remédier aux limitations de la bande passante PCIe lors de la communication entre ses GPU de centres de données de premier plan. Chaque génération est devenue plus rapide et la bande passante actuelle atteint aujourd'hui des vitesses fulgurantes de 900 Go/s par GPU. Chaque génération est devenue plus rapide et la bande passante actuelle atteint aujourd'hui des vitesses fulgurantes de 900 Go/s par GPU, soit environ 7 fois plus que les vitesses PCIe Gen 5 traditionnelles, tout en étant 5 fois plus économe en énergie que PCIe Gen 5. Cette technologie d'interconnexion, autrefois réservée aux GPU de NVIDIA, a été ouverte pour permettre la communication de puce à puce (C2C). Cela ne concerne pas seulement la Grace Hopper Superchip, mais aussi l'intégration semi-personnalisée au niveau du silicium, car les conceptions futures seront de plus en plus accélérées et basées sur les puces.

ARCHITECTURE DE SUPER-PUCE GRACE HOPPER
Le CPU Grace de NVIDIA est la première version d'un CPU de centre de données doté de 72 cœurs Arm Neoverse V2, la conception de cœurs ARM la plus performante. Comme indiqué précédemment, le processeur Grace dispose de 512 Go de mémoire cohérente et comme il s'agit de LPDDR5X, il est à la fois économe en énergie et rapide avec 546 Go/s de bande passante mémoire par CPU. Comparée à une conception DDR5 traditionnelle à 8 canaux, la mémoire de Grace offre jusqu'à 53 % de bande passante en plus pour une fraction de la puissance. Le GPU associé ici est Hopper, la 9ème génération de GPU pour centres de données de NVIDIA. Il fait déjà l'objet d'une forte demande à l'heure actuelle, la tendance à l'IA s'étant emparée du marché. L'architecture Hopper a également été la première à être commercialisée sous la forme d'une mémoire HBM3, dont 96 Go se trouvent dans la puce Grace Hopper de NVIDIA, ce qui permet d'obtenir une bande passante mémoire de 3 To/s. Hopper bénéficie également d'un plus grand nombre de multiprocesseurs de streaming, d'une fréquence plus élevée et de nouveaux cœurs Tensor de 4ème génération ; tout cela peut être exploité par le nouveau moteur Transformer pour un débit potentiellement multiplié par 6 par rapport à l'A100, le précédent GPU phare de NVIDIA pour les centres de données. Le diagramme de cette architecture et de ses principales caractéristiques est présenté ci-dessous :
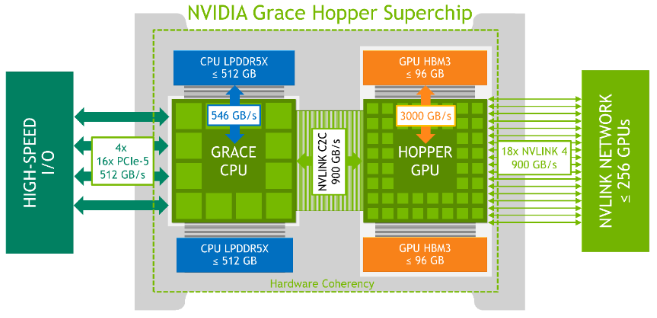
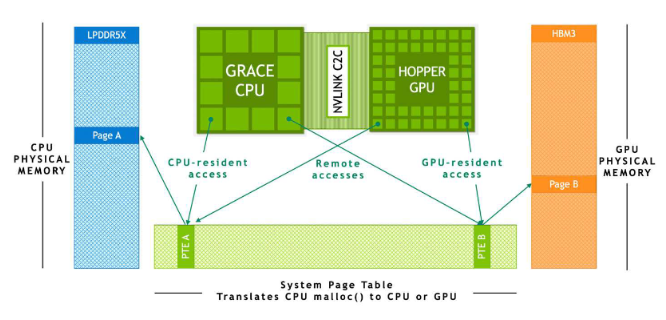
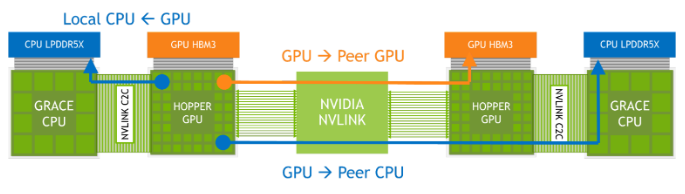
Le système de commutation NVLink de 4ème génération de NVIDIA peut connecter directement jusqu'à 8 superchips Grace Hopper par NVSwitch. De plus, un deuxième niveau dans une topologie fat-tree permet de mettre en réseau jusqu'à 256 superchips Grace Hopper. Lorsque les 256 superchips sont connectés, ce réseau peut fournir une bande passante totale de 115,2 To/s. Ce chiffre est 9 fois plus élevé que celui de la bande passante totale de l'ensemble des superchips. C'est 9 fois plus que la bande passante de NVIDIA Infiniband NDR400. La 4ème génération de NVIDIA NVLink permet aux threads GPU d'adresser jusqu'à 150 To de mémoire à partir de tous les superchips Grace Hopper du réseau pour les opérations mémoire normales, les transferts en masse et les opérations atomiques. Cela permet également aux bibliothèques de communication telles que MPI, NVSHMEM et NCCL d'exploiter de manière transparente le système de commutation NVLink. NVIDIA appelle cette fonction Extended GPU Memory (EGM). Cette fonction est spécialement conçue pour les applications nécessitant des empreintes mémoire massives - plus grandes que la capacité locale (HBM3 + LPDDR5X) d'une seule super-puce Grace Hopper. L'EGM permet aux threads du GPU d'accéder à toutes les ressources mémoire à des vitesses de 450 Go/s via la structure NVSwitch, à la fois pour HBM3 et LPDDR5X.
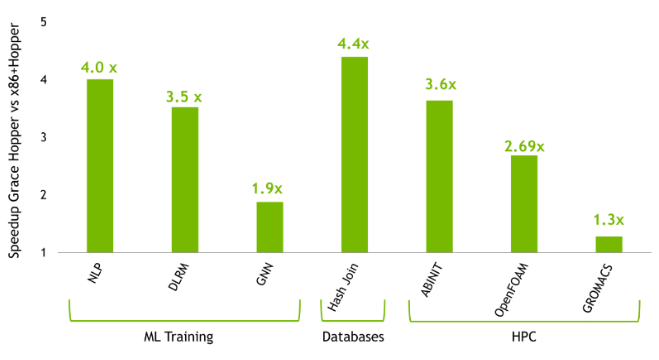
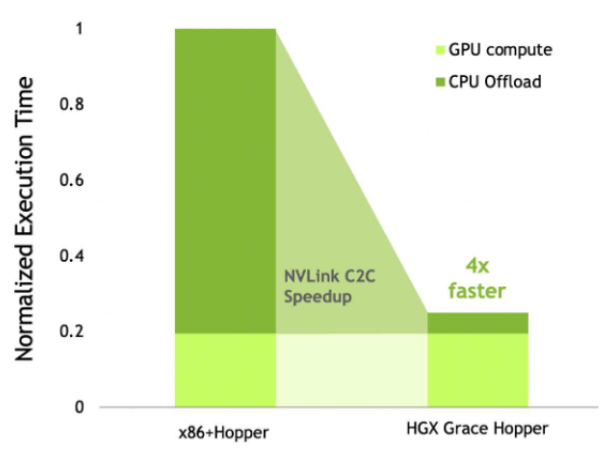
Nous avons déjà abordé les principales caractéristiques de conception de Grace Hopper, à savoir son interconnexion C2C et la manière dont ces superpuces s'étendent via NVLink, mais pas encore son ratio GPU/CPU de 1:1. Cette conception hétérogène est particulièrement adaptée au calcul intensif (dynamique des fluides, modélisation météorologique/climatique et dynamique moléculaire), à l'apprentissage automatique (systèmes de recommandation, traitement du langage naturel et réseaux neuronaux graphiques) et aux bases de données. Vous trouverez ci-dessous un aperçu de la vitesse des applications des utilisateurs finaux dans les domaines susmentionnés, Grace Hopper étant comparé à un système x86 + Hopper traditionnel.
BASES DE DONNÉES
Les charges de travail des bases de données ont des tables d'entrée remarquablement grandes qui ne tiennent pas dans la mémoire du GPU. Par conséquent, les performances sont souvent limitées par le transfert de données entre le CPU et le GPU via la liaison PCIe. Le NVLink C2C de Grace Hopper atténue cette limitation de la bande passante car le CPU et le GPU construisent simultanément une table de hachage partagée pour les jointures et les regroupements. Cela permet de tirer parti de l'accès aux sites de mémoire HBM3 et LPDDR5X, qui sont cohérents sur le plan matériel. Ci-dessous, nous pouvons voir des comparaisons de performances entre HGX Grace Hopper et un système x86 + Hopper traditionnel. Simulations de performances pour la jointure de hachage avec des tables d'entrée dans la mémoire du processeur (à gauche) et le transfert d'hôte à périphérique de la mémoire résidente hôte paginable (à droite).
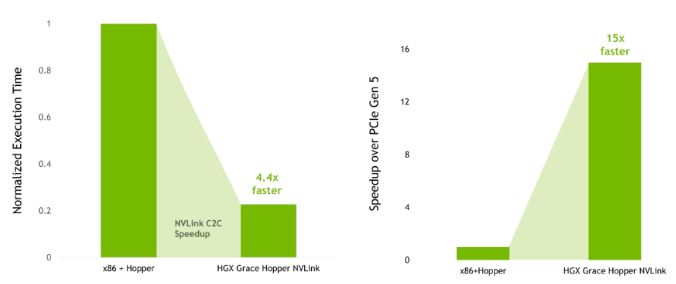
TRAITEMENT DU LANGAGE NATUREL
L'IA et les grands modèles de langage (LLM) ont fait la une des journaux ces derniers mois, leur taille et leur complexité augmentant rapidement depuis quelques années. Open AIs ChatGPT utilise son modèle GPT-4 le plus récent, qui aurait franchi la barre des 1 000 milliards de paramètres. Il existe de nombreux modèles concurrents dont les paramètres se chiffrent également en centaines de milliards. Tous ces modèles massifs sont entraînés sur de très grands ensembles de données à l'aide d'énormes grappes de GPU pendant des mois. Comme vous pouvez l'imaginer, il s'agit d'un processus incroyablement coûteux. Pour obtenir des réponses de meilleure qualité de la part d'un LLM, des techniques d'ingénierie rapide sont utilisées, mais cela prendrait énormément de temps pour des centaines de milliards de paramètres. Une technique plus efficace pour les LLM consiste à utiliser le P-tuning (prompt tuning), qui consiste à accorder un modèle beaucoup plus petit avant le LLM. Le P-tuning permet d'économiser beaucoup de temps et de ressources car il peut être réalisé en quelques heures plutôt qu'en plusieurs mois. Les résultats de ce P-tuning sont sauvegardés en tant que tokens virtuels dans une table de recherche pour l'inférence, remplaçant le modèle plus petit. L'entraînement est beaucoup plus rapide avec ces modèles et ces ensembles de données plus petits, ce qui permet un réentraînement itératif des tâches de traitement du langage naturel (NLP) qui évoluent au fil du temps. Bien que le P-tuning soit moins gourmand en ressources, il bénéficie toujours d'une bande passante mémoire rapide pour le déchargement du tenseur. Sur les systèmes x86, l'accès à la mémoire système nécessaire est limité par la liaison PCIe, mais avec la super-puce Grace Hopper, le NVLink C2C permet un accès rapide à la mémoire LPDDR5X. Cela réduit donc considérablement le temps d'exécution du déchargement du tenseur lors du P-tuning par rapport à un système x86 + Hopper, comme le montre l'exemple ci-dessous avec un modèle GPT-3 175B.
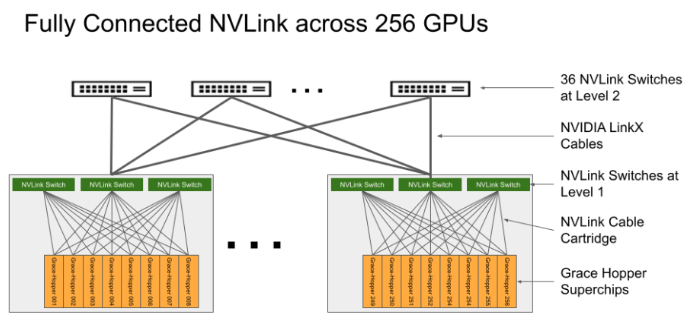
NVIDIA a également annoncé son DGX H200, qui est essentiellement son plan de référence pour l'évolutivité massive des charges de travail HPC et AI les plus importantes au monde. Le DGX GH200 dispose de 256 superchips Grace Hopper avec un mélange de mémoire légèrement différent de celui mentionné précédemment, 96 Go de HBM3 et 480 Go de LPDDR5. Le système de commutation NVLink de 4ème génération de NVIDIA permet à l'ensemble des 144 To de mémoire d'être accessibles aux GPU au sein du réseau. Le GH200 est le premier supercalculateur à franchir la barre des 100 To pour l'accès à la mémoire d'un GPU. Les cartes de base hébergeant les superpuces Grace Hopper sont connectées au système de commutation NVLink à l'aide d'un faisceau de câbles personnalisé pour la première couche de tissu NVLink. Les câbles LinkX étendent ensuite la connectivité de la deuxième couche à 36 commutateurs NVLink, comme illustré ci-dessous.
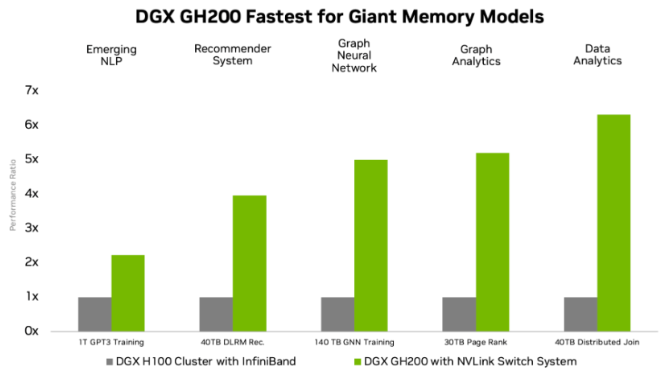
For every Grace Hopper superchip in the DGX GH200 there is also a NVIDIA ConnectX-7 network adapter and a NVIDIA Bluefield-3 NIC. For solutions where you need to scale beyond 256 GPUs, the ConnectX-7 adapters can interconnect multiple DGX GH200 systems for an even larger supercomputer. The inclusion of Bluefield-3 DPUs allows organisations to run applications in multi-tenant, secure environments. A lot of HPC and AI workloads can fit within the aggregate GPU memory of a single DGX H100, in such cases the DGX H100 is still the most performant solution. However, many AI & HPC models are requiring massive memory capacity to house their workloads, this is what the DGX GH200 is purpose built for and truly excels at. The speedups of which are demonstrated below.
NVIDIA prévoit de rendre DGX GH200 disponible à la fin de cette année. Mais la plateforme Grace Hopper Superchip HGX sera disponible dans les mois à venir ici à Boston. La photo ci-dessous montre l'ARS-221GL-NR de Supermicro prenant en charge le Superchip Grace Hopper de NVIDIA, qui sera bientôt disponible. Les spécifications complètes du système doivent encore être confirmées - nous mettrons à jour dès que possible ; n'hésitez pas à nous contacter pour manifester votre intérêt dès maintenant, car la demande devrait être énorme.

