

Boston est ravi d'annoncer notre partenariat avec DDN !
Dans les coulisses, notre équipe de Boston Labs a effectué des tests de performances sur le DDN A3I AI400X avec le NVIDIA DGX-A100.
FLEXIBILITÉ EFFICACE, ET PUISSANTE
Les solutions de stockage DDN A3I sont entièrement optimisées pour accélérer les applications d'apprentissage automatique et d'intelligence artificielle (IA), rationalisant les flux de travail d'apprentissage profond (DL) pour une plus grande productivité. Les solutions de stockage d'intelligence artificielle A3I exploitent les connaissances des déploiements éprouvés par les clients pour faciliter l'innovation alimentée par l'IA. L'AI400X est une infrastructure de stockage de données IA clé en main pour un déploiement rapide, offrant des performances plus rapides, une évolutivité sans effort et des opérations simplifiées grâce à une intégration profonde avec les systèmes GPU NVIDIA.
RÉFÉRENCE DDN VS RESNET DE STOCKAGE LOCAL
Le test de performance suivant a été effectué pour comparer l'adéquation d'une matrice flash AI400X à un RAID 100% Flash local pour les charges de travail AI.
DDN AI400X
Que vous accélériez une charge de travail d'analyse, réduisez les latences pour les bases de données NoSQL difficiles, ou débutez un projet d'apprentissage profond avec des ensembles de formation modestes, la plate-forme AI400X NVMe est un élément de base idéal et rentable. Conçue pour tirer le meilleur parti de votre investissement, la structure interne PCIe Gen 3 à 192 voies extrait le plus de performances de la mémoire flash, permettant de nouveaux cas d'utilisation de la bande passante et des IOP, couplée à la puissance d'un système de fichiers parallèle hautement adapté aux charges de travail GPU. De plus, les données sont accessibles via des protocoles standard de fichiers et d'objets pour une flexibilité ultime.
RESNET50
Pour mesurer les performances du système DDN AI400X, nous avons utilisé l'implémentation optimisée ResNet v1.5 pour MXNet fournie par NVIDIA via le NVIDIA GPU Cloud que vous pouvez voir ici.
ResNet est un raccourci pour Residual Network et, comme le nom du réseau l'indique, le réseau s'appuie sur l'apprentissage résiduel (qui tente de résoudre les défis liés à la formation des réseaux de neurones profonds. Ces défis incluent une difficulté accrue à s'entraîner à mesure que nous approfondissons, ainsi que saturation et dégradation de précision. ResNet est disponible en deux versions : ResNet-50 ou ResNet-152 (où ResNet 50 est un réseau résiduel de 50 couches et 152 est un réseau résiduel de 152 couches). Pour cette référence, nous nous sommes concentrés sur ResNet-50, en utilisant deux des tailles de lots les plus courantes.
Le benchmark a été exécuté pendant 30 époques avec des tailles de lots de 192 et 384. Chaque test a été effectué trois fois et les nombres indiqués sont la moyenne de ceux-ci. L'ensemble de données standard ImageNet 2012 a été utilisé.
DGX-A100
Pour le calcul, le NVIDIA DGX-A100 a été utilisé. Le DGX-A100 est un système d'IA intégré de 3e génération avec 5 PetaFLOPS de performances dans un seul nœud. Doté de 8 GPU NVIDIA A100, d'un SSD NVMe de 15 To Gen4, de 6 commutateurs NVSwitches et de 9 interfaces réseau Mellanox ConnectX-6 200 Gb / s, le DGX A100 peut être utilisé pour l'analyse de données, l'inférence et la formation, avec la possibilité de diviser les ressources GPU et de les partager entre 56 utilisateurs différents. Le DGX A100 est élastique pour le calcul évolutif et évolutif !
Résultats :
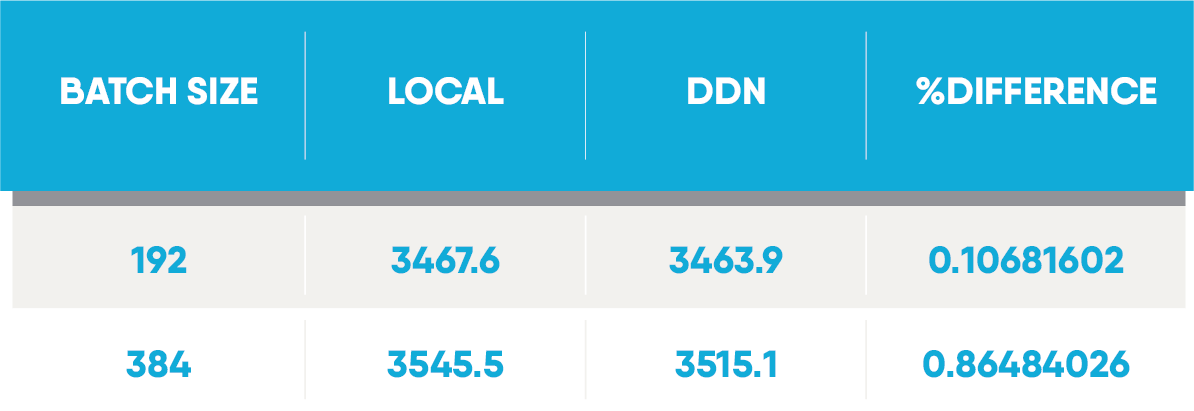
Ces résultats montrent que lors de l'utilisation du stockage AI400X de DDN avec un DGX-A100, les performances sont presque identiques à celles d'un RAID 100% Flash local. Avec des lots de 192 et 384, nous n'avons observé qu'une baisse des performances de 0,1% et 0,86% respectivement.
Les étapes détaillées sur la façon dont le benchmark a été réalisé peuvent être trouvées ici.
Si vous avez des questions sur les points de repère ci-dessus ou si vous souhaitez vous renseigner sur votre propre essai routier, notre équipe de Boston Labs se tient à votre disposition pour vous aider. Notre équipe commerciale est également disponible pour répondre à toutes vos questions concernant l'une des solutions mentionnées sur servicespro@boston-it.fr
